ITA Word Numbers Solution
Creation date: 2 october 2007
Contents
- Abstract
- Introduction
- Problem definition
- Goal
- Searching for the 51 billionth letter
- Summing the integers
- Conclusion
- Credits and Links
Abstract
I implemented a solution for the ITA word number puzzle. The program output is:
The letter is: e It is in position 77 in the following string: sixhundredseventysixmillionsevenhundredfortysixthousandfivehundredseventyfive ...which has length: 77 The sum up to and including this number is: 413540008163475743 real 0m0.166s user 0m0.136s sys 0m0.032s
You can download the source code file WordNumbers.java, or view the pretty-printed version in my subversion repository.
Introduction
One fine day, while I was wwilfing, I encountered the ITA word number puzzle. Rather frighteningly, it jumped out of my browser window and grabbed hold of my throat, refusing to let go until it was solved. Struggling for breath, I wasted a week and them some of productive time implementing a solution.
... As if I didn't have anything better to do. The kids are going hungry, the mortgage needs to be paid, the wife is yapping about my lacking household participation, my boss is seriously wondering what the heck I'm doing. But no, I just had to solve this puzzle, universe be damned. Thank god I managed it today, I can breathe a sigh of relief and continue with my normal life.
What you will find here is my solution described in words, along with an implementation in java. The functional model is quite elegant, if I may say so myself. The implementation, it goes without saying, is another matter and displays its warts under scrutiny. I resisted the urge to weed out the bad stuff; I almost succeeded.
Feel free to contact me if you feel like corresponding about this document.
Kind Regards,Wim.
Problem Definition
To be precise: if the integers from 1 to 999,999,999 are expressed in words (omitting spaces, 'and', and punctuation[1]), and sorted alphabetically so that the first six integers are
- eight
- eighteen
- eighteenmillion
- eighteenmillioneight
- eighteenmillioneighteen
- eighteenmillioneighteenthousand
- twothousandtwohundredtwo
The 51 billionth letter also completes the spelling of an integer. Which one, and what is the sum of all the integers to that point? [1] For example, 911,610,034 is written "ninehundredelevenmillionsixhundredtenthousandthirtyfour"; 500,000,000 is written "fivehundredmillion"; 1,709 is written "onethousandsevenhundrednine".
The problem is split into two parts:
- Searching for the 51 billionth letter, and determining the corresponding integer.
- Summing the integers, which are sorted alphabetically, up to and including found integer.
Goal
The goals I want to achieve within the context of this problem are:
-
Exorcize this problem.
For my own piece of mind, I need to get this thing out of my head. If I don't bury it quickly, it will continue to haunt me and eat at my productivity.
-
Aim for the solution, not for perfection.
I am looking for the answer of the problem, I do not intend to create the cleanest, smartest, most paradigm-filled, complete solution possible. Contrary to my primal perfectionist urges, I will stop at 'good enough'.
No real attempt at encapsulation, commenting, refactoring is made. No snazzy OO techniques will be used, no agile programming enhancements will be applied. If you find this revolting, that is entirely your problem. This is solution oriented programming, as opposed to ego-manifesting programming.
-
Apply java 5 features.
While I'm at it, I will use some of the new enhancements of java 5 as a finger-flexing exercise.
Searching for the 51 billionth letter
After much doodling, I got the idea of creating a grammar for the word numbers, out of which all possible legal text representations of values could be generated. Calculating the lengths should be easy then, it's a question of traversing all possible paths and summing up the lengths of all words encountered.
Performance can be improved by taking into account that many elements in the syntax are repeated and can thus be reused in the grammar. Repeating elements need to be calculated only once, the result can be used many times as appropriate.
Syntax graphs
The grammar for the word number is displayed in graph-form below. The term Graph is also used in the code to label the corresponding data structures. The graphs have been translated directly into data structures in the code.
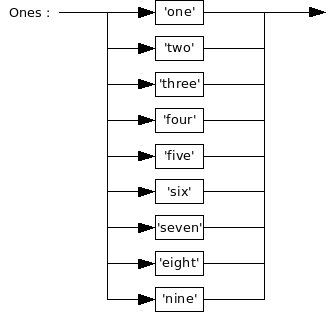
Ones-Graph
The Ones-graph defines the single-digit numbers 1 to 9.
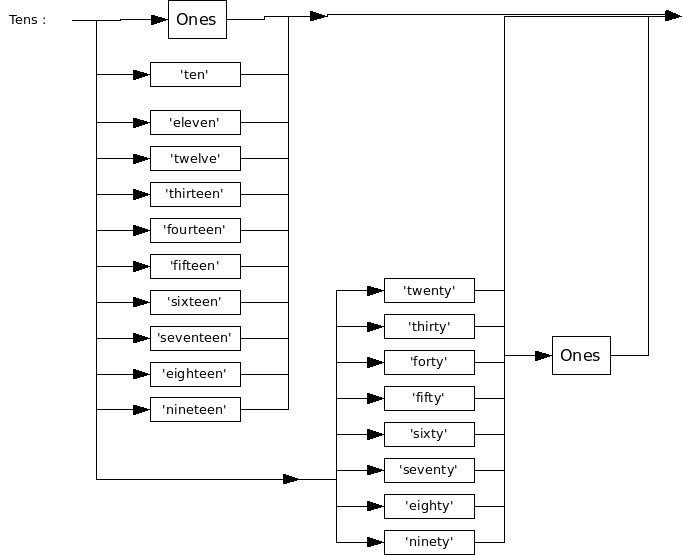
Tens-Graph
The Tens-graph defines the grammar for all word numbers from 1 to 99. It could have been defined more efficiently; this is the definition I used in the program. As you can see, the Ones-graph is used twice within this graph.
Hundreds-Graph
The Hundreds-graph defines the grammar for all word numbers from 1 to 999.

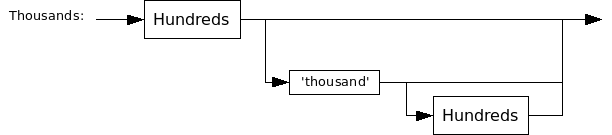
Thousands-Graph
The Thousands-graph defines the grammar for all word numbers from 1 to 999,999.
Millions-Graph
The Millions-graph defines the grammar for all word numbers from 1 to 999,999,999. This is the top-level graph, from which the calculation starts.

Search Strategy
The algorithm for finding the requested letter, and the encompassing word number, is as follows:
1. Initialize the graph
Create the Millions-Graph. This data structure is a direct translation of the syntax graph. All subgraphs are retained.
2. Sum the word lengths per node
This involves traversing through the graph, summing per node over the lengths of all strings and doing the same over all child nodes. The accumulating sum over all word lengths, and also the sum of all paths traversed, is stored in every node. This cuts down the processing time because most nodes have multiple parent nodes, so the summing does not need to be redone when a node is encountered which has already been visited. In any case, this information per node is needed in the calculation later on.
3. Determine the first child nodes
From the parent node of the graph, make a list of all word nodes which are connected directly to the parent node. These nodes are brought to the front of the graph and replace the original connected nodes. Since nodes can be connected as child-nodes muliple time, the found word-nodes are copied. Information of subgraphs is discarded in this step. The graph is changed in this step, i.e. this algorithm is destructive.
4. Sort and index the first child nodes
The list of child nodes created in step 3 is sorted alphabetically. Since the total length of the corresponding strings following these nodes is known, it is now possible to determine the starting index of the sequence of letters represented by these nodes. The index is stored within the node.
The effects of sorting are discussed further below under Sorting child nodes.
5. Determine node corresponding to solution
We now know the starting index and range of letters per node, which helps us determine the node at this level corresponding to the index we are searching for. The found node is the first part of out solution.
6. Repeat from step 3. on found node
The search process can be repeated on the found node to determine the rest of the solution. The iterations continue till the last node in the graph is encountered. You should now have the solution.
Sorting child nodes
The result of sorting the first level is displayed in the following diagram:
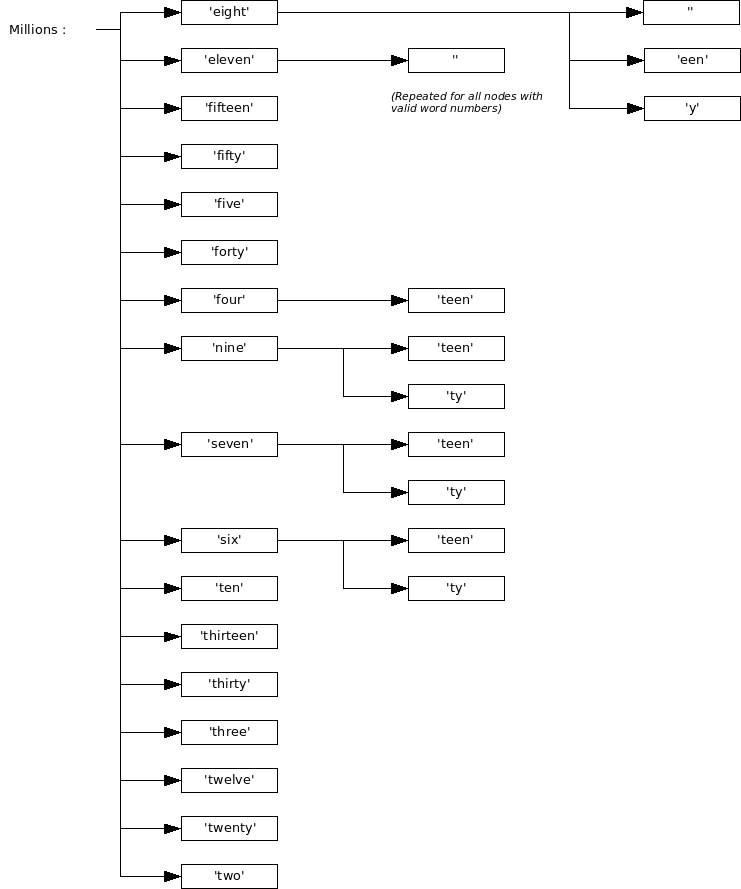
The following remarks need to be made:
- Subsequent nodes are not displayed in this diagram.
- A node with an empty string indicates the end of a legal word number. The parent node is likely to have more child nodes; for instance 'six' is legal, but so is 'sixty', 'sixhundred', 'sixtysixthousand', etc.
- The sort needs to be unambiguous. In order to achieve this, some nodes need to be split, for instance 'eighty' into 'eight' and 'y'. Note that this need not be done exhaustively; for example 'forty' and 'four' are distinct in the sorting order, and need not be split into 'fo' and a node containing the rest. Problems may occur when a word is the same or a substring of an other word, as in 'four' and 'fourteen'.
- Multiple occurences of the same value are common; these are combined into a single node, onto which all child nodes of all previous instances are attached.
- After the sorting, the current level is clean. Lower levels, however, may be a mess, containing multiple equivalent instances in unsorted order. This does not influence the calculation in any way, at least for the nodes outside of the solution we are seeking. For the solution itself, the next node in line is simply determined and the sorting process is done over its child nodes.
Splitting legal words further was a pretty smart move for determining the requested letter, if I may say so myself (quick pat on the back). However, it totally screwed up the calculation of the sum of integers in the next part of the puzzle. My self-satisfied smirk got quickly polished away after repeated attempts at being smart about this. In the end I settled for recombining the split nodes before summing, a clumsy fix for a likely unnecessary problem. Oh well.
Summing the integers
Inspired by the quick success of determining the requested letter and integer, I enthusiastically jumped into coding the summing part. I tried to be clever about it, which was exactly the wrong thing to do. Many failed attempts later, I gave up and resorted to the brute force approach of following every path and summing all found values. In order to aid this, I progressively removed in the searching step all the nodes from the graph whose word number values are alphabetically after the found solution.
After choosing this approach, two optimizations became apparent:
Accumulator objects for storing interim values
The processing of the modifiers ( 'hundred', 'thousand', 'million' ) was a bitch to handle programmaticaly. It occurred to me that a better approach was create a storage class which kept track of the positions relative to the modifiers. That way, when a modifier is encountered, all you need to do is shift the current numbers to the next appropriate position. This simplified the calculation significantly.
The storage class is defined as follows:
class NumberAccumulator {
long tens; // Smallest digits
long hundred; // Digits before first 'hundred'
/* digits before first 'thousand' */
long tens_th;
long hundred_th;
/* Digits directly before 'million' */
long tens_m;
long hundred_m;
/* Digits before the 'thousand million' */
long tens_th_m;
long hundred_th_m;
/** Move digits to before 'hundred'. */
void doHundred() { ... }
/** Move digits to before 'thousand'. */
void doThousand() {... }
/** Move digits to before 'million'. */
void doMillion() { ... }
...
}
Basically, all integer values are added into the 'tens' variable. When a modifier value 'hundred', 'thousand' or 'million' is encountered, the corresponding 'doXXX()' method is called. This method shifts the tens value (and all other variables of course) into the other variables as necessary. The final value is the sum over all variables, taking the modifiers into account.
Subgraphs need not be traversed; the answer is known beforehand
Most subgraphs have survived the previous step, and their presence can be used to make the calculation more efficient. The sum over the elements in a subgraph is trivial, and the number of paths through them is known. The sum, in fact, can be derived directly from the number of paths through the equation:

The values for the subgraphs are:
| Graph | Sum | Paths |
|---|---|---|
| Ones | 45 | 9 |
| Tens | 4950 | 99 |
| Hundreds | 499500 | 999 |
| Thousands | 499999500000 | 999999 |
In fact, the main graph was initialized as the Millions-graph)
These values can be used directly in the calculation. The calculation for the subgraphs is thereby avoided.
Summing Strategy
The algorithm for summing the alphabetically sorted integers, up to and including the solution, is as follows:
1. Combine the regular nodes
All consecutive nodes which are not modifiers ( 'hundred', 'thousand', 'million' ) are collected into single nodes. For example, nodes 'eighty' and 'eight' will become one node 'eightyeight'.
This simplifies the handling of the modifier nodes. In addition, nodes split due to sorting are recombined in this manner.
Subsequent steps are performed by iterating over the nodes, beginning at the start of the graph.
2. Apply modifier values
If current node contains 'hundred', 'thousand' or 'million', shift the values in the accumulator instance accordingly.
3. Iterate over child nodes
Perform the calculation for the subsequent nodes; if there aren't any, just return the value of the current node. The sums of the child nodes are added to the current sum.
4. Calculate subgraphs
When a subgraph is encountered, return the precalculated sum instead of traversing the subgraph. Continue the calculation with the node(s) directly following the subgraph.
This is not as trivial as it appears; see handling subgraphs here below for a discussion.
Handling subgraphs
Taking number of paths into account
With the summing of the subgraphs I ran into caveats which could not be solved by obstinate, persevered coding. Stepping back a bit, I analyzed the graph handling mathematically to understand the problem, which follows below.
When multiple subgraphs follow each other, the number of paths of each graph needs to be taken into account. Consider the following sequence, which occurs within the graph:

Assume that an interim sum is present, which is passed from the parent nodes. We will call this sum Prefix. The calculation for this particular path becomes:
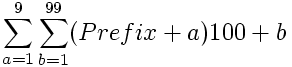
Collecting the sums into the sums of the individual subgraphs results in:
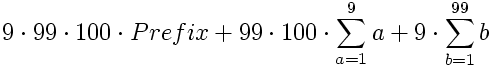
Rearranging and substituting more meaningful names:
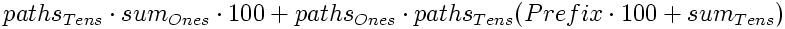
Where:
- pathsX - Number of paths through graph X
- sumX - Sum of all values within graph X
This arrangement implies a possible approach to handling the graph sums. Given that the current node is a graph node, the approach is:
- Continue sum calculation over subnodes without adding the sum of the current graph.
- Multiply result with the number of paths in the current graph.
- Iterate over subnodes with the sum value of the graph, without summing the values of the subnodes; i.e. only take modifiers into account.
- Multiply result with the number of paths in the preceding node(s) of the current graph.
Setting accumulator values for graphs
While it is trivial to calculate the sum over all the values in a graph, it is necessary to take into account any modifiers affecting a graph. The summed value of the graph needs to be split properly into the variables as defined by the NumberAccumulator class.
This it trivial for the Ones and Tens graph; just add the entire sum to the tens-variable. For the hundreds node, we can determine the following:
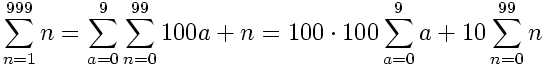
So the corresponding accumulator instance should be loaded as follows:
NumberAccumulator val = new NumberAccumulator(); val.tens = 10*sumOver(99); val.hundred = 100*sumOver(9);
Similarly, the sum for the thousand-values becomes:
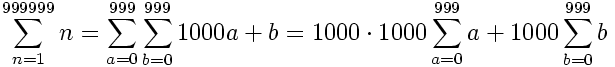
In other words, the sum over the hundreds is repeated in the thousands-position and all values are multiplied by thousand. The accumulator instance is instanced as follows:
NumberAccumulator val = new NumberAccumulator(); val.tens = 1000*10*sumOver(99); val.hundred = 1000*100*sumOver(9); val.tens_th = 1000*10*sumOver(99); val.hundred_th = 1000*100*sumOver(9);
Conclusion
I solved the problem, I can continue with my life. Halleluja! I was quite impressed with its complexity, which was not so obvious in the definition. Smart people at ITA for thinking this up, I tip my hat before you.
Although solving it was harder than expected, I am quite pleased with my result, which in essence is quite elegant (less so in practise), and performs adequately, in tenths of seconds.
Usage of java 5 elements uncovered at least one point which I find frustrating with respect to generics and the new for-loop construct. I defined an abstract node class for the graph, which served as superclass for the classes which are more specific to this problem:
abstract class Node implements Comparable<Node> {
Vector<Node> next = new Vector<Node>();
Vector<Node> previous = new Vector<Node>();
...
}
class NumberNode extends Node {
...
}
Now I want to iterate over the next and previous lists, using the derived classes:
class NumberNode extends Node {
...
void someMethod() {
// Java says no; incompatible types
for ( NumberNode node: next ) {
...
}
}
...
}
This looks obvious to me and I would expect it to work, java opinions otherwise. I can live with it with some apprehension. If someone knows how to iterate elegantly, please let me know.
Finally, if give a warm and sincere thank you to the ITA folk for presenting me this challenge. Now excuse me while I get on with my life.
Credits and Links
- Honourable mention for Matt Reynolds, who found the solution before me ( readme.txt, number.c, rules.txt), and whose result I used to verify my own calculation.
- The ITA Word Numbers puzzle.
- Forum discussion about the puzzle.
- Equations created with Roger's Online Equation Editor.
- Graphs created with Open Office.
- HTML coded with gVim.